

Introducing RGB-Stacking as a new standard for vision-based robotic processing
Picking up a stick and balancing it on a tree trunk or stacking a pebble on a stone might seem like simple actions – and quite similar – to someone. However, most bots struggle to handle more than one task at a time. Stick manipulation requires a different set of behavior than stacking stones, let alone stacking different dishes on top of each other or grouping furniture. Before we can teach robots how to perform these kinds of tasks, they first need to learn how to interact with a much larger variety of objects. As part of DeepMind’s mission and as a step toward making bots more generalizable and useful, we are exploring how to enable bots to better understand the interactions of objects with diverse geometries.
In a paper to be presented at CoRL 2021 (the Robot Learning Conference) and now available as a preprint on OpenReview, we introduce RGB-Stacking as a new standard for vision-based machine manipulation. In this standard, the robot must learn to understand and balance different objects on top of each other. What sets our research apart from previous work is the variety of objects used and the large number of empirical evaluations carried out to validate our findings. Our results demonstrate that a combination of simulation data and real-world data can be used to learn the complex manipulation of multiple objects and suggest a strong baseline for the open problem of generalizing to new objects. To support other researchers, we’re open-source a copy of our simulated environment, and release designs to build a real robot RGB stacking environment, along with RGB object models and information for 3D printing for them. We also open source a range of libraries and tools used in our robotics research more broadly.
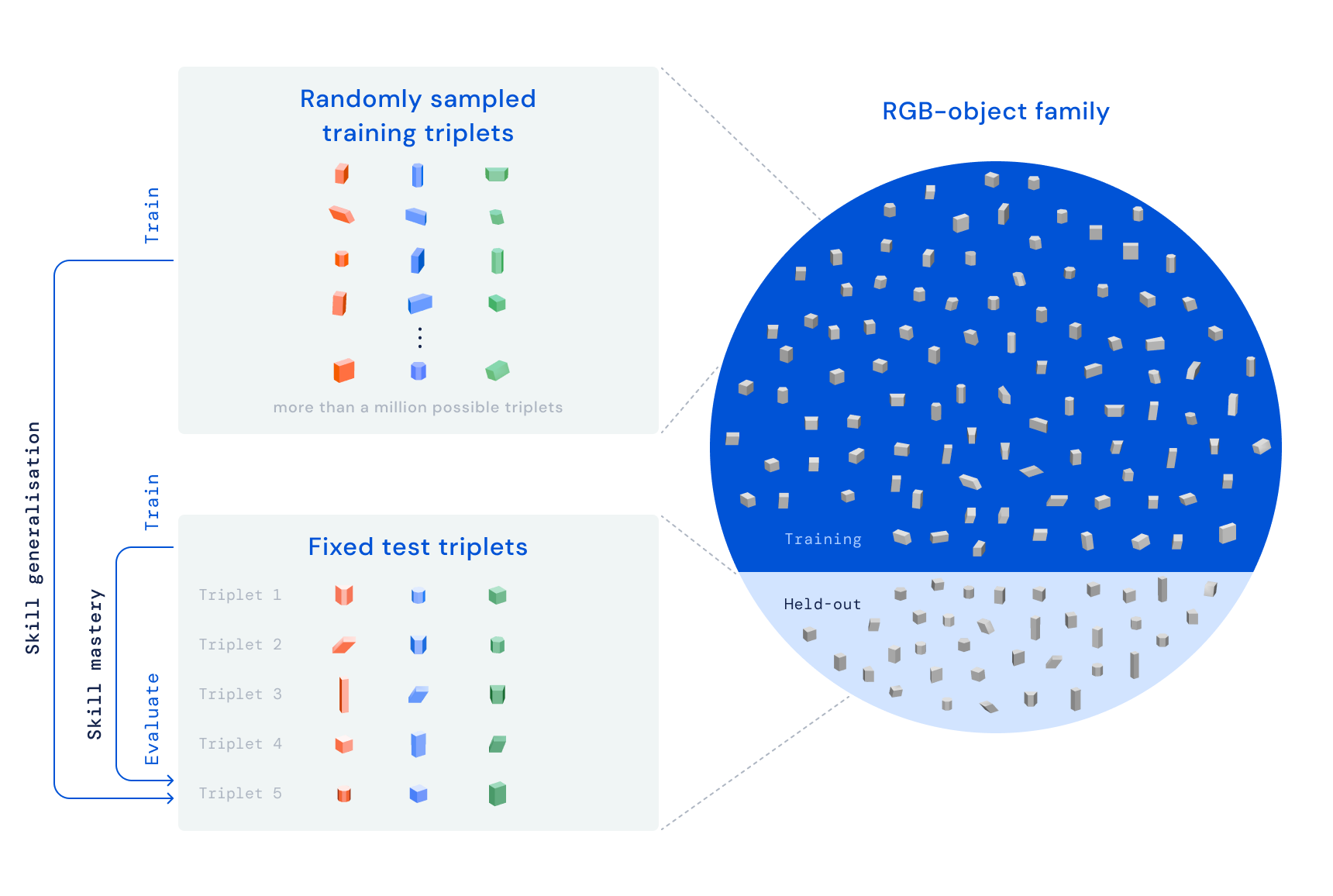
With RGB-Stacking, our goal is to train a robotic arm through reinforcement learning to stack objects of different shapes. We place a parallel gripper attached to a robot arm over a basket, and three things in the basket – one red, one green, and one blue, hence the name RGB. The task is simple: stack the red object on top of the blue object within 20 seconds, while the green object acts as an obstacle and distraction. The learning process ensures that the agent acquires generic skills through training on multiple object combinations. We intentionally change the comprehension and stack capabilities — the attributes that determine how the agent can ingest and stack each object. This design principle forces the agent to display behaviors beyond a simple pick-and-place strategy.

Our RGB-Stacking benchmark includes two versions of tasks with different levels of difficulty. In Mastering the Skill, our goal is to train a single agent who is skilled at stacking a predetermined group of quintuplets. In Skill Generalization we use the same triplets for evaluation, but we train the agent on a large set of training objects – totaling over a million possible triplets. To test generalization, these training objects exclude the family of objects from which triplets were selected. In both versions, we separate our learning path into three phases:
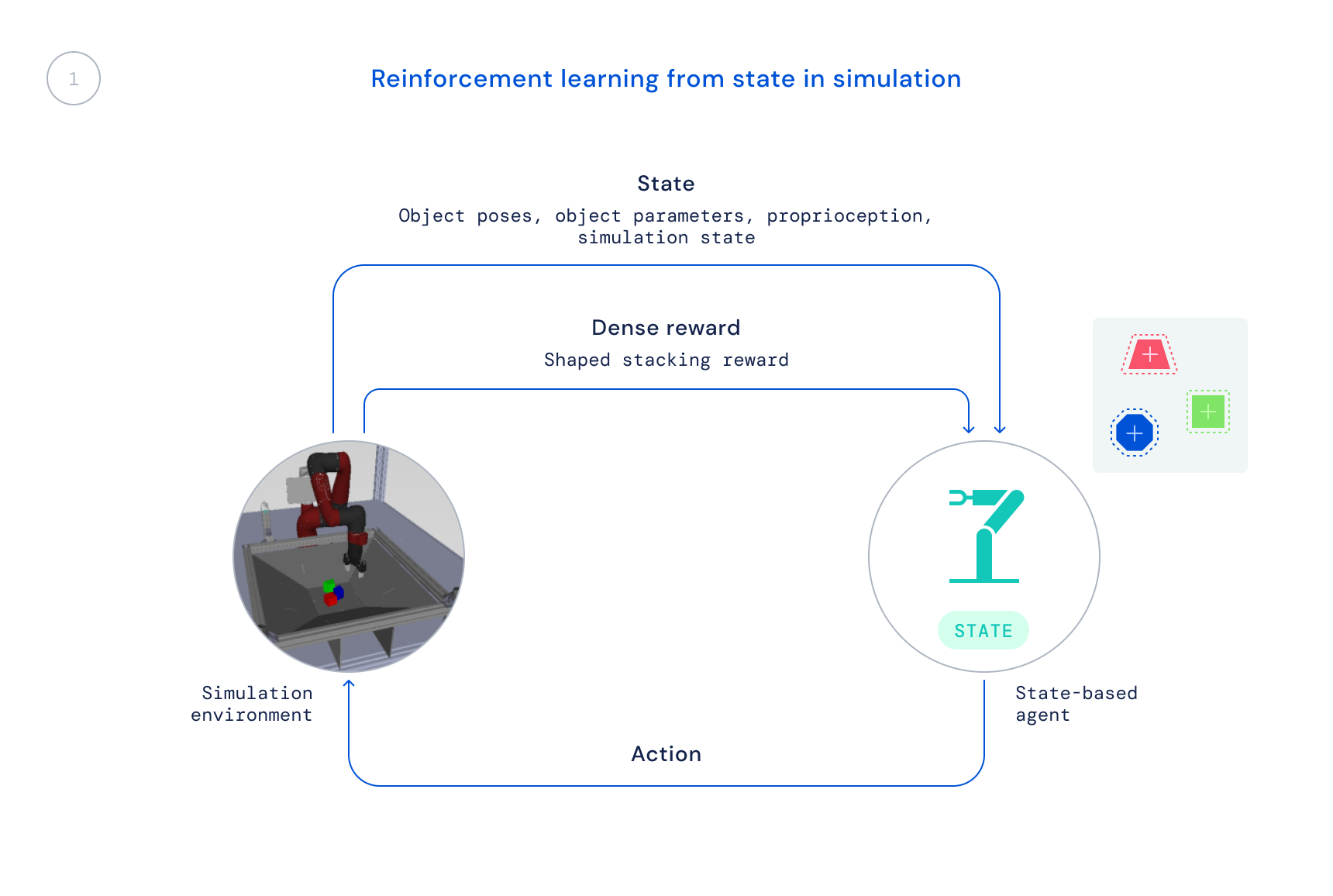
- First, we train the simulation with a ready-made RL algorithm: maximum post policy optimization (MPO). At this point we use the state of the simulator, which allows for fast training as the object positions are given directly to the agent rather than the agent needing to learn how to find the objects in the images. The resulting policy is not directly transferable to the real bot because this information is not available in the real world.
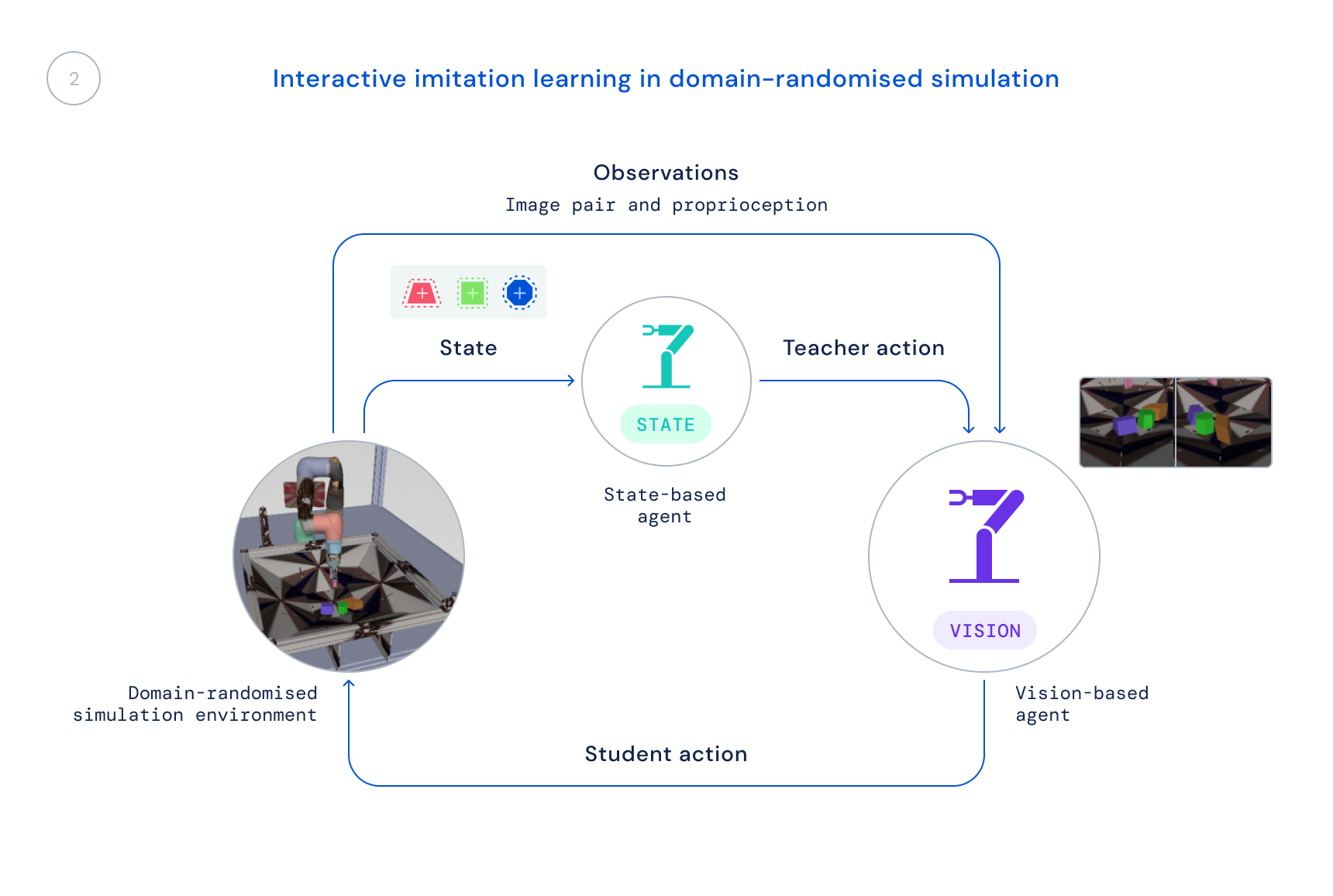
- Next, we train a new policy in the simulation that uses only real-world observations: images and the robot’s self-stimulus condition. We use random field simulations to improve transfer to real-world images and dynamics. State policy acts as a teacher, providing the learning agent with corrections to his behaviour, and these corrections are distilled into the new policy.
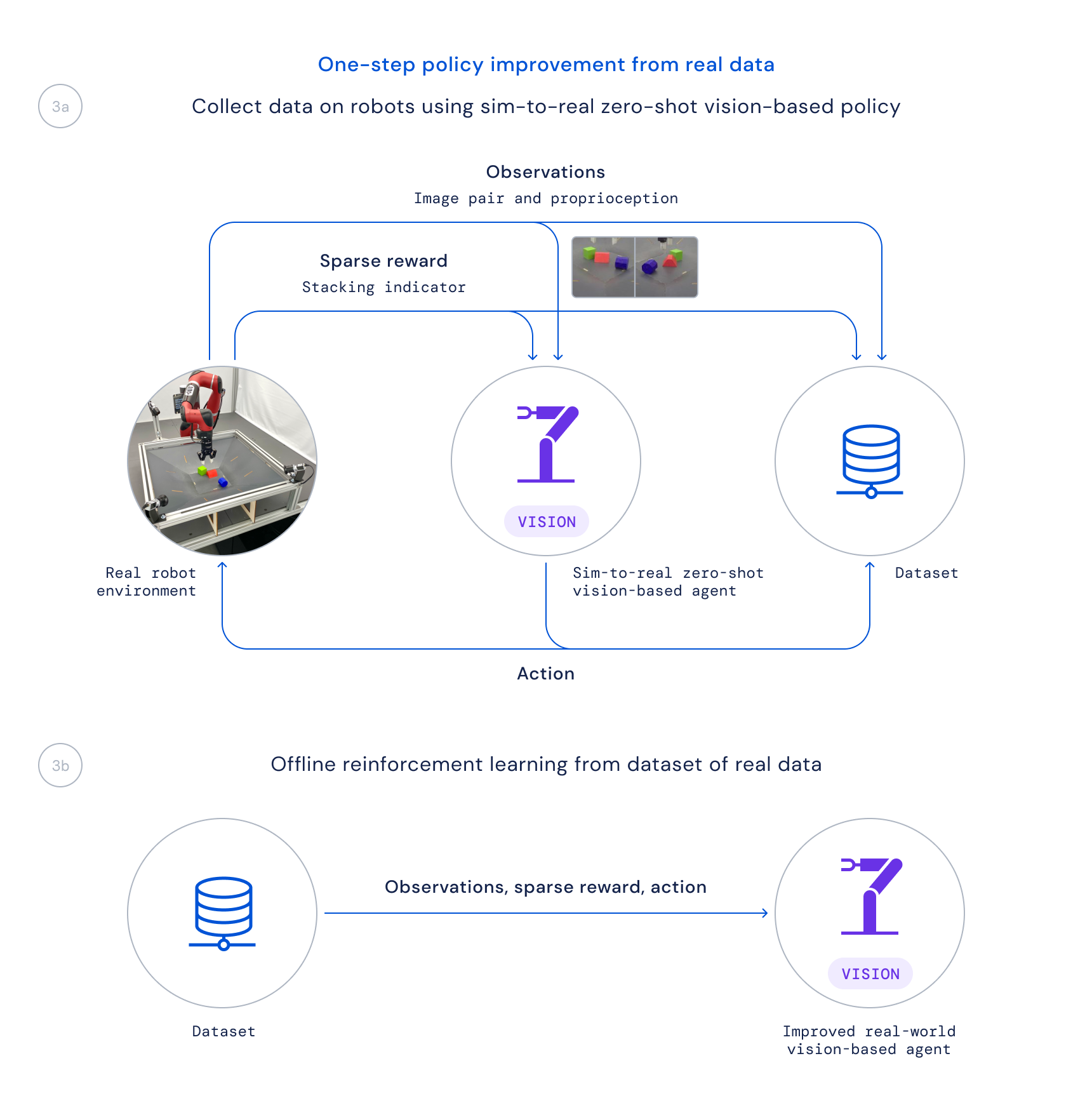
- Finally, we collect data with this policy on real bots and train an optimized policy from this data offline by evaluating good transitions based on the learned Q function, as in critically structured regression (CRR). This allows us to passively use the data collected during the project rather than running a time-consuming online training algorithm on real bots.
Separating our learning path in this way proves crucial for two main reasons. First, it allows us to solve the problem at all, since it would take a long time if we wanted to start from scratch on the bots directly. Second, it speeds up our search, since different people on our team can work on different parts of the pipeline before integrating these changes for an overall improvement.

In recent years, there has been a lot of work on applying learning algorithms to solve challenging real robot manipulation problems on a large scale, but the focus of this work has been largely on tasks such as push grabs or other forms of manipulating individual objects. The RGB-Stacking approach we describe in our paper, combined with the robotics resources we now have on GitHub, results in amazing stacking strategies and stack proficiency for a subset of these objects. However, this step only scratches the surface of what is possible – and the challenge of generalization remains not fully resolved. As researchers continue to work on the open challenge of true generalization in robotics, we hope that this new standard, together with the environment, designs, and tools we have released, will contribute to new ideas and methods that can make manipulation easier and robots more capable.